
As the world goes digital, the data it generates explodes:

Companies can exploit the potential that data brings. Use Artificial Intelligence (AI) to mine the data. However, AI requires tons of refined data to work. As Data is the new oil, to get value out of it, you need data refineries. Companies accelerate their AI projects to produce competitive advantage/s.
Big Data has issues
Figure 1source:https://rctech.org/blogs-about-data-management/poor-data-quality-is-expensive-and-may-stab-your-business.html
Accelerate AI projects with Data Refineries
Big Data is messy. It is incomplete. It is not consistently recorded. It may not be accurate. It needs to be consolidated. It can be enhanced with other data. Data Refineries do ETL workloads (Extract, Transform and Load). This is 80% of workload of Analytic or AI training projects. Data refineries gather, clean and repurpose data. They enrich the data. They filter out ambiguity. Data Refineries then hand over their output to data science teams. These Data science teams do the actual number crunching. Their output can either be insights or trained models.
Companies benefit from offloading the ETL part to Data refineries. Instead of having their data science teams do the ETL process themselves. This results in a leaner team.
Data Refineries in CRISP-DM
All Data projects start with the Business Need. What insight or model can the company use to create a competitive advantage? Once companies know the question, it proceeds to Data Collection. This stage gathers data. Traditionally, companies look at transactional data. Feature engineering filters down records to needed variables.
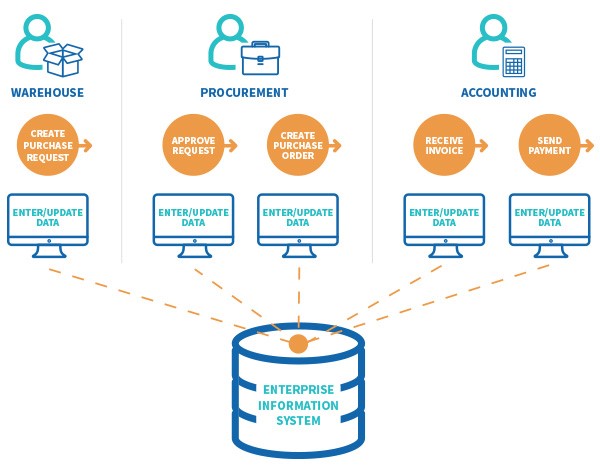
Figure 2 source: https://www.winshuttle.com/adm-blog/data-quality-issues/
Data Refineries then ‘enrich’ this data. We add dark data.

Figure 3 source: http://www.m-files.com/blog/sink-swim-managing-growing-flood-dark-data-eim/
Mobile Apps might provide demographic and social graph data. Company help desk might provide product feedbacks. A company’s Social media accounts might provide sentiment data. Want to learn more? Chat with us or drop us an email.

